Reinforcement Learning with Human Feedback (RLHF) is a subfield of machine learning. It focuses on how artificial intelligence (AI) agents can learn from human feedback. AI agents are trained to align with human preferences.
They learn to take action in an environment to maximize a reward signal. The agent receives feedback from a human teacher in the form of positive or negative reinforcement.
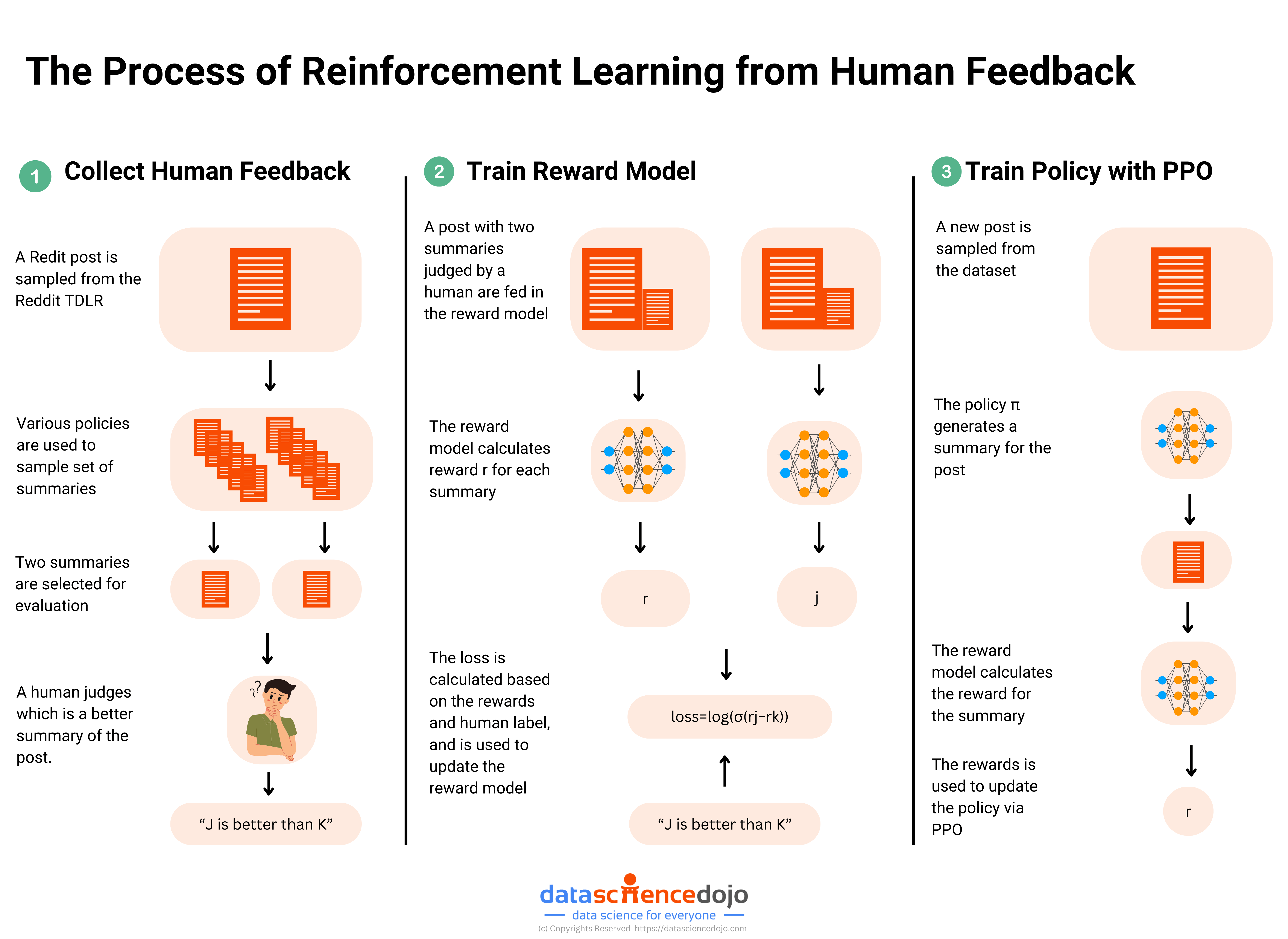
Traditional reinforcement learning relies on a predefined reward function. RLHF addresses the challenge of defining a reward function that accurately captures human preferences. It does this by training a "reward model" directly from human feedback.
This allows the agent to learn from a broader range of experiences. It also learns more efficiently, as it can learn from the expertise and perspective of a human.
Human feedback is crucial. It provides a nuanced understanding of complex tasks and preferences that are hard to define algorithmically. Humans rank or rate the AI's performance.
This feedback trains the reward model. The reward model then guides the AI in making better decisions.
ChatGPT's training involves several stages. This includes pre-training, supervised fine-tuning, reward model training, and reinforcement learning fine-tuning. Human feedback plays a critical role in the latter stages.
Human trainers provide feedback on the model's responses. This feedback is used to train a reward model that guides the reinforcement learning process.
ChatGPT is first pre-trained on a massive dataset of text. It is then fine-tuned using supervised learning on a smaller dataset of human-written demonstrations. This initial training helps the model understand language and generate coherent text.
The model is further fine-tuned using reinforcement learning. It is guided by a reward model trained on human feedback.
Human feedback helps ChatGPT align its responses with human values and preferences. This is particularly important for complex tasks such as generating creative content, providing helpful information, and avoiding harmful outputs. Human trainers rate the model's responses based on quality, relevance, and safety.
This feedback is used to train a reward model. This model then guides the reinforcement learning process, helping the AI make better decisions.
ChatGPT builds upon the techniques developed for InstructGPT. InstructGPT was one of the first models to demonstrate the effectiveness of RLHF in aligning language models with human instructions. ChatGPT uses a similar approach.
It adds improvements in data collection and training stability. Both models use human feedback to train a reward model.
One example of RLHF in ChatGPT is its ability to generate more helpful and contextually relevant responses. When you ask ChatGPT a question, it generates a response based on its training. If the response is not satisfactory, you can provide feedback.
This feedback is used to improve the model over time. You might rate the response or provide a better alternative.
Human feedback significantly enhances the performance and accuracy of machine learning models. By incorporating human judgment, models can achieve a deeper understanding of complex tasks and user preferences. Human feedback helps models improve by learning from their mistakes.
It also helps them adapt to new situations. This leads to better performance in real-world applications.
Many tasks are difficult to define algorithmically. Human feedback allows models to learn these complex tasks by understanding human preferences. For example, generating creative content or providing personalized recommendations requires understanding nuanced human preferences.
RLHF enables models to learn these preferences from human feedback. This feedback provides a more accurate signal than predefined rules.
Human feedback helps reduce bias in AI systems. By providing feedback on a diverse range of examples, human trainers can help models learn to make fair and unbiased decisions. This is particularly important for applications where fairness is critical.
Examples include hiring, loan applications, and criminal justice. RLHF ensures that AI systems align with ethical principles and societal values.
Reinforcement learning has numerous real-world applications. It has shown great promise across various domains. These include autonomous vehicles, robotics, finance, and more.
These applications demonstrate the versatility and power of RL. They also show its potential to solve complex real-world problems.
Autonomous vehicles use reinforcement learning to navigate complex traffic situations. They learn to make decisions such as lane changing, overtaking, and parking. For example, Wayve.ai has successfully applied reinforcement learning to train a car on how to drive in a day.
The agent learns by interacting with its environment. It receives rewards for safe driving and penalties for unsafe actions.
Robots use reinforcement learning to perform tasks such as assembly, packing, and sorting. For instance, Deepmind used AI agents to cool Google Data Centers, leading to a 40% reduction in energy spending. The agent learns by interacting with the environment.
It receives rewards for efficient performance and penalties for errors. Robots can learn to perform tasks more efficiently than humans.
Reinforcement learning is used in finance for tasks such as portfolio optimization and algorithmic trading. For example, IBM has a reinforcement learning based platform that has the ability to make financial trades. The agent learns by interacting with the market.
It receives rewards for profitable trades and penalties for losses. RL can help make better investment decisions.
The field of reinforcement learning is rapidly evolving. There are many exciting trends and potential developments on the horizon. These include advances in deep reinforcement learning, transfer learning, and multi-agent systems.
These advancements promise to further enhance the capabilities of AI systems. They will enable them to tackle even more complex and challenging tasks.
Using human feedback in AI training raises several ethical considerations. One concern is the potential for bias in the feedback. Human trainers may have unconscious biases that can influence the model's behavior.
It is crucial to ensure diversity among trainers. Also, implement methods to detect and mitigate bias in the feedback.
Collecting high-quality human feedback is challenging. It requires careful design of feedback mechanisms and quality control processes. Feedback can be subjective and vary among different trainers.
It is important to provide clear guidelines and training to human annotators. This ensures consistency and reliability of the feedback.
Ensuring fairness in AI systems is a critical challenge. RLHF can help reduce bias by incorporating diverse human perspectives. However, it is essential to actively monitor and address potential biases in the training data and feedback.
Techniques such as adversarial training and fairness constraints can be used. They promote fairness and mitigate bias in AI models.
Reinforcement Learning with Human Feedback (RLHF) is a powerful technique. It aligns AI systems with human preferences and values. Human feedback plays a crucial role in training AI models like ChatGPT.
It enhances their performance, addresses complex tasks, and reduces bias. RLHF has numerous real-world applications, including autonomous vehicles, robotics, and finance.
Key Takeaways:
- RLHF leverages human feedback to train AI models, making them more aligned with human preferences.
- ChatGPT uses RLHF to improve its ability to generate helpful, relevant, and safe responses.
- Human feedback enhances model performance, addresses complex tasks, and reduces bias.
- RL has diverse applications, including autonomous vehicles, robotics, finance, and healthcare.
- Ethical considerations, such as bias and fairness, are crucial in the development and deployment of RLHF systems.
Continued research in RLHF is essential to unlock its full potential. Further advancements in algorithms, data collection methods, and ethical guidelines will enhance the capabilities and reliability of AI systems. Collaboration between researchers, industry professionals, and policymakers is crucial.
It ensures that RLHF is developed and deployed responsibly. This will benefit society as a whole.