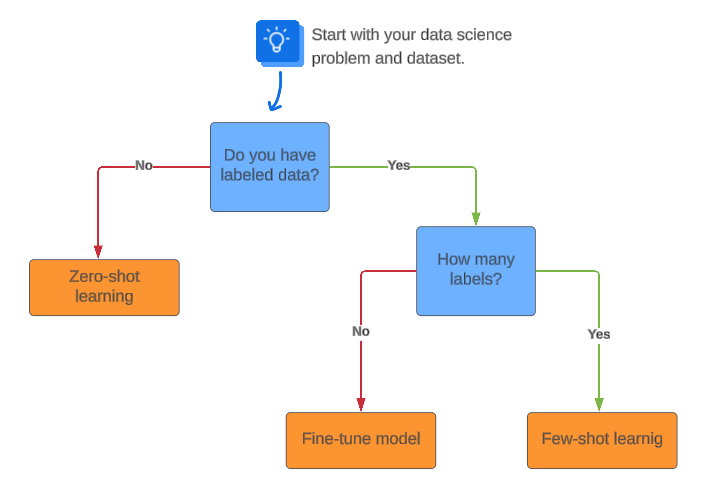
Zero-shot text classification is a fascinating approach in natural language processing (NLP). It allows a model to classify text into categories it has never seen during training.
This technique enables models to handle new, unseen classes without requiring labeled data for those specific categories. It is a powerful tool for adapting to constantly evolving data landscapes.
Traditional text classification relies on training models with labeled data for each category. If you want to classify news articles into "sports", "politics", and "technology", you need examples of each.
Zero-shot learning breaks this mold. It can classify text into new categories like "entertainment" or "finance" without ever seeing examples of those during training. This is because the model learns to understand the underlying meaning and relationships between words and concepts, a technique also known as transfer learning.
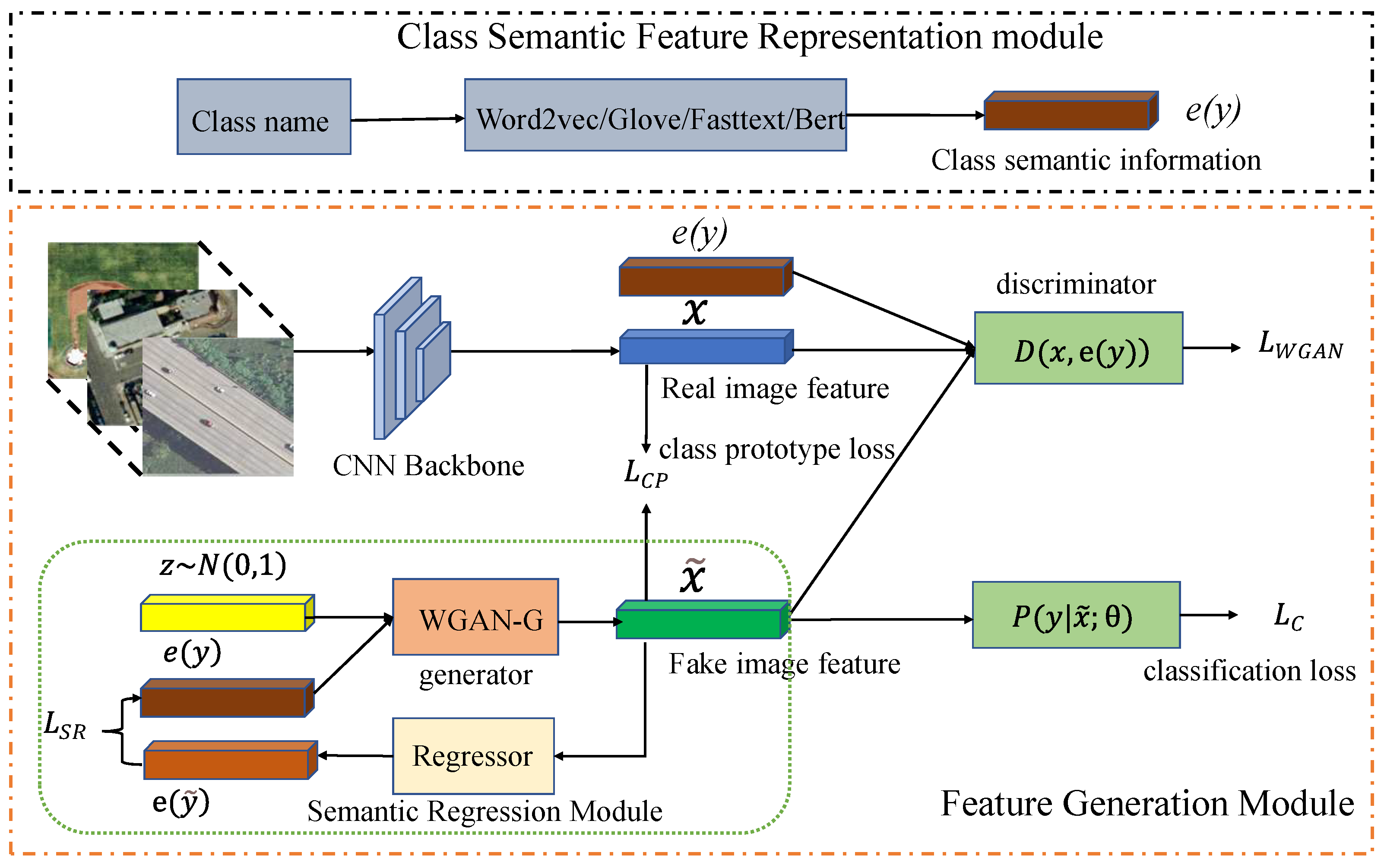
Pre-trained language models are the backbone of zero-shot text classification. Models like BERT, RoBERTa, and others are trained on massive amounts of text data.
They learn to understand language nuances, context, and relationships between words. This vast knowledge allows them to generalize to new tasks, including classifying text into unseen categories, similar to LLM prompting.
Class embeddings are crucial for zero-shot learning. Each class is represented as a vector in a semantic space.
These vectors capture the meaning of the class. For example, "sports" might be close to "football" and "basketball" in this space. Similar to how vector databases work, this allows the model to understand relationships between classes.
Natural Language Inference (NLI) plays a vital role. NLI models determine the relationship between a premise and a hypothesis.
In zero-shot learning, the text to be classified is the premise. The hypothesis is a statement like "This text is about [class]". The model predicts whether the premise entails the hypothesis.
One major advantage is the reduced need for labeled data. Traditional methods require extensive labeled datasets, which can be expensive and time-consuming to create, especially when dealing with deep learning algorithms.
Zero-shot learning eliminates this requirement for new classes. This makes it much easier to adapt to new categories as they emerge.
Hugging Face's Transformers library is a popular tool for implementing zero-shot classification. It provides pre-trained models and easy-to-use pipelines for this task.
You can quickly set up a classifier with just a few lines of code. The library handles the complexities of model loading and inference.
from transformers import pipelineclassifier = pipeline("zero-shot-classification", model="facebook/bart-large-mnli")text = "Apple just launched a new iPhone with advanced AI features."candidate_labels = ["technology", "finance", "sports"]result = classifier(text, candidate_labels)print(result)
Zero-shot classification has numerous real-world applications. It can be used for content moderation on social media platforms to identify new types of harmful content.
In customer service, it can categorize customer feedback into emerging issues. E-commerce platforms use it to classify new product listings. Even fields like medical diagnosis can benefit, as explained in "Unlocking the Power of Zero-Shot Classification: A Primer".
Data scarcity is a challenge, even for zero-shot learning. While you don't need labeled data for new classes, the model still needs to understand the general concept.
Ambiguity can also be a problem. Some classes might be too similar, making it difficult for the model to distinguish between them.
Zero-shot learning is a rapidly evolving field. Ongoing research aims to improve accuracy and efficiency.
We can expect to see more robust models capable of handling a wider range of classes. Integration with other techniques, like few-shot learning, will likely enhance performance.
Zero-shot text classification is transforming how we approach NLP tasks. It offers a flexible, adaptable, and cost-effective solution for classifying text.
Its ability to handle new classes without labeled data opens up exciting possibilities. As the technology matures, it will play an increasingly important role in various applications, from content moderation to personalized recommendations, and even exploring open-source text-to-image models.
Key Takeaways:
Zero-shot classification enables models to classify text into categories they haven't seen during training.
Pre-trained language models and class embeddings are crucial components of this technique.
It reduces the need for labeled data, offering flexibility and cost-effectiveness.
Hugging Face Transformers library simplifies implementation.
Despite challenges, zero-shot learning holds immense potential for the future of NLP.