Transformers are a type of deep learning model. They were introduced in the 2017 paper "Attention Is All You Need" by researchers at Google.
They are designed to handle sequential data, like text, but unlike recurrent neural networks (RNNs), they process the entire input all at once. This makes them very efficient for natural language processing (NLP) tasks.
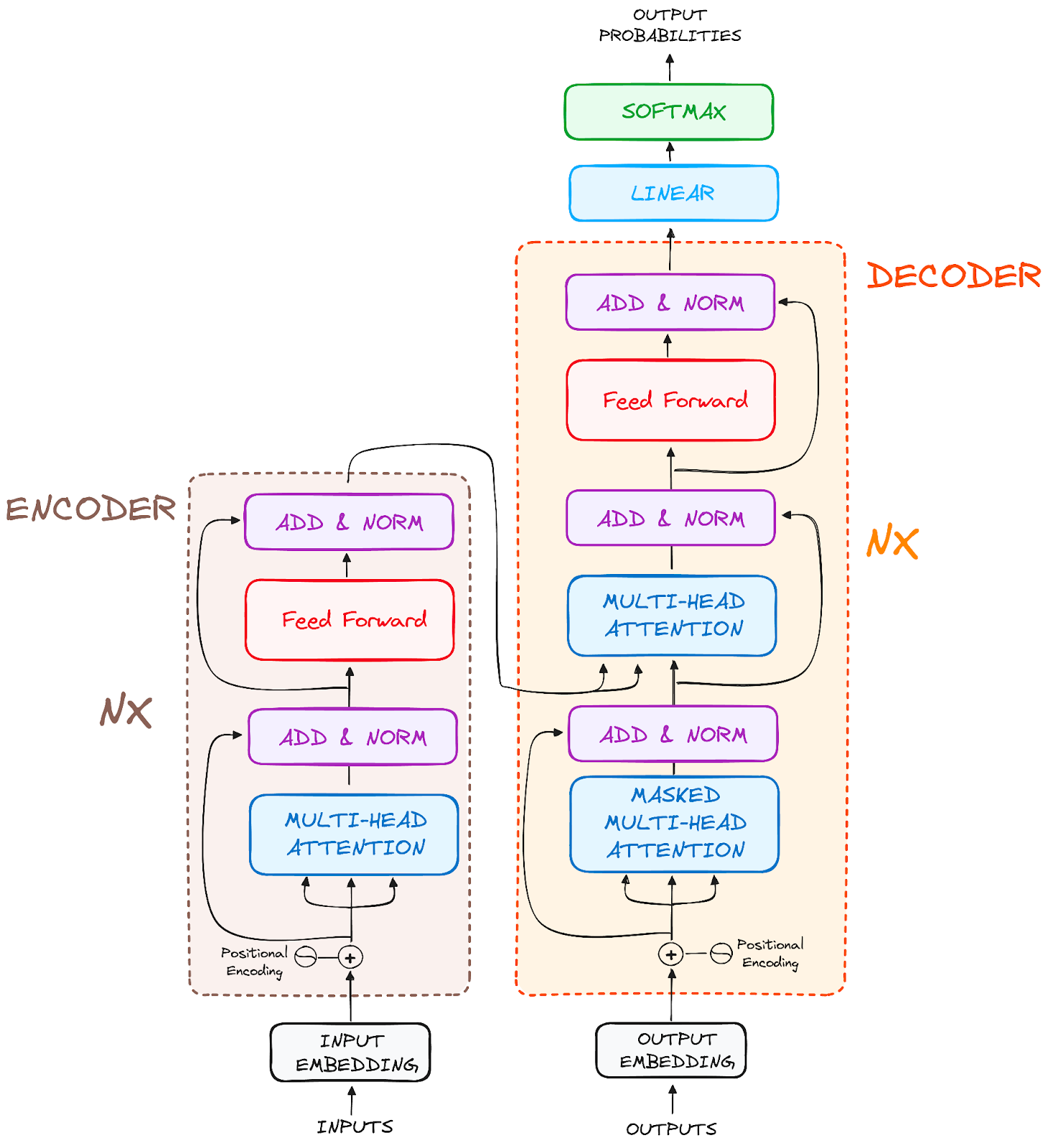
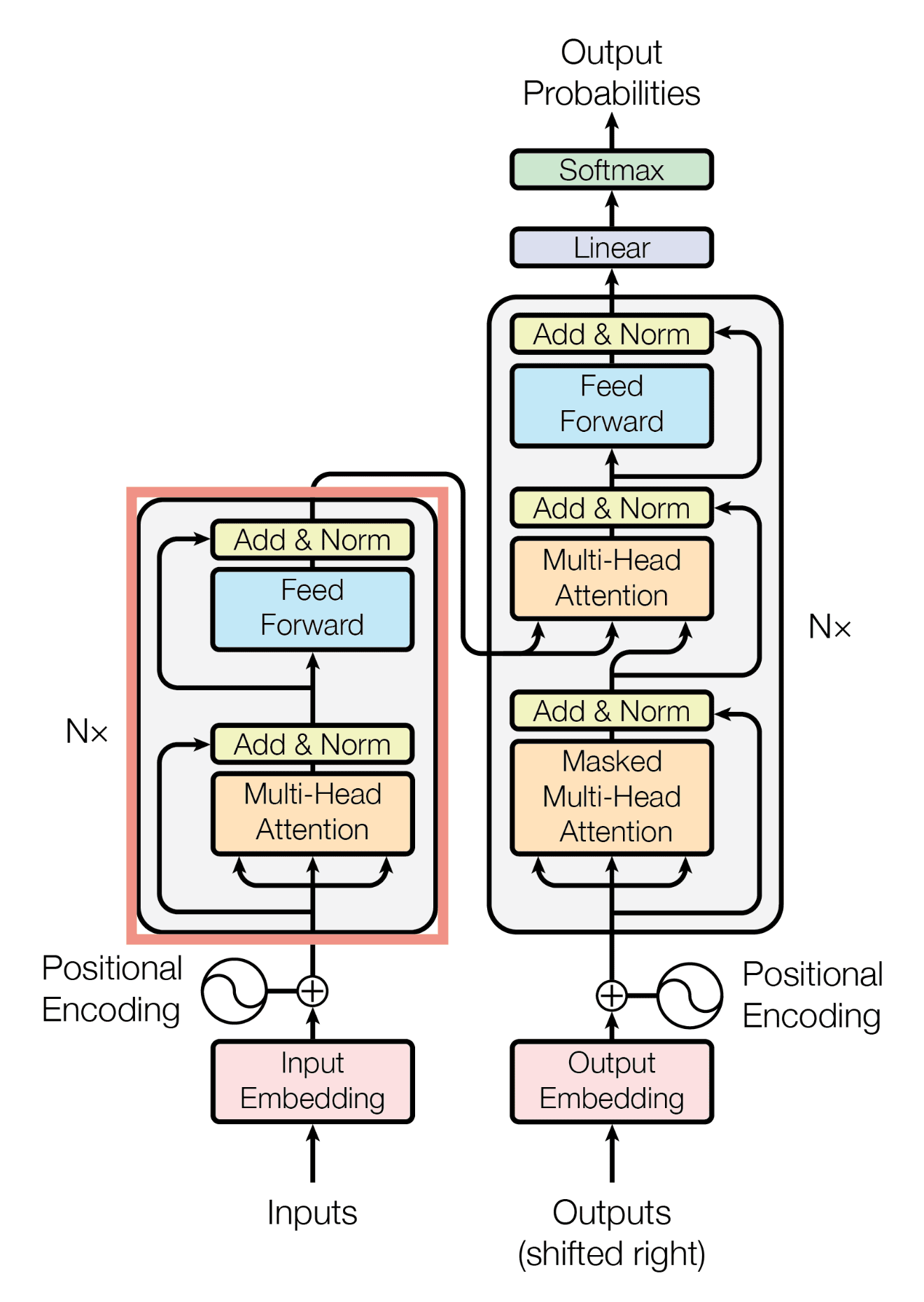
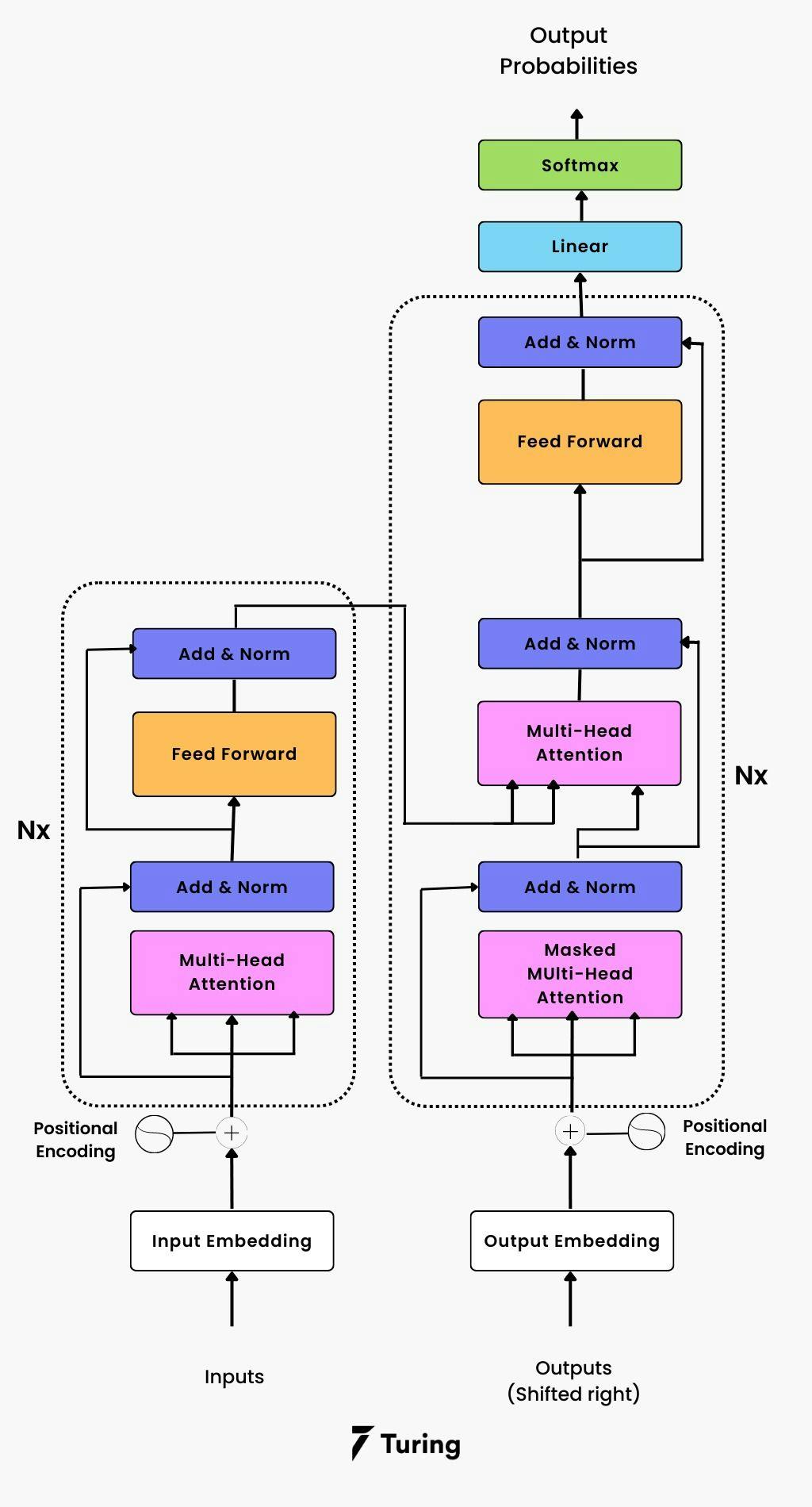
This is the core innovation of transformers. Self-attention allows the model to weigh the importance of each word in a sentence relative to all other words.
This helps capture contextual relationships, even between distant words. For instance, it helps understand that "it" refers to "the cat" in the sentence "The cat sat on the mat because it was tired".
Since transformers don't process data sequentially, they need a way to understand word order. Positional encoding adds information about the position of each word in the input sequence.
This ensures that the model can distinguish between "John loves Mary" and "Mary loves John."
First, the input text is broken down into individual words or tokens. Each token is then converted into a numerical representation called an embedding.
These embeddings capture semantic meaning. Similar words have similar embeddings.
The self-attention mechanism is applied multiple times in parallel, which is called multi-head attention. Each "head" learns to focus on different aspects of the input.
For example, one head might focus on grammatical relationships, while another focuses on semantic relationships. The outputs of all heads are combined to create a richer representation.
The decoder takes the encoded representation and generates the output sequence one token at a time. It uses attention to focus on the relevant parts of the encoded input.
It also considers the previously generated tokens. This allows it to produce coherent and contextually appropriate output.
Transformers excel at understanding context. The self-attention mechanism allows them to consider the entire input sequence when processing each word.
This leads to a deeper understanding of the relationships between words and phrases. For example, the model can understand the sentiment expressed in a sentence and translate it to another language.
Transformers are also very effective for sentiment analysis. They can accurately classify the sentiment of a piece of text, such as positive, negative, or neutral.
This is useful for understanding customer feedback and social media trends. This is also one of the tasks that Meta's Llama 3.3 70B excels at.
Transformers can generate concise and informative summaries of long documents. They can identify the most important information and present it in a clear and coherent manner.
This is useful for quickly getting the gist of news articles, research papers, or other long texts.
Transformers are now being used in computer vision tasks. They can achieve state-of-the-art results in image classification, object detection, and image segmentation.
They are able to capture long-range dependencies in images, which is difficult for traditional convolutional neural networks (CNNs).
Transformers are also making inroads in audio and speech processing. They are used for tasks like speech recognition, speech synthesis, and music generation.
Their ability to model long-range dependencies is particularly useful in these domains.
Transformers are being applied to various healthcare tasks. For instance, they can analyze medical images, predict patient outcomes, and assist in drug discovery.
AlphaFold3 uses a transformer-based model to predict protein structures, which is crucial for understanding diseases and developing new treatments.
The use of transformers is likely to continue expanding into new domains. Their ability to model complex relationships in sequential data makes them a powerful tool for a wide range of AI applications.
Researchers are exploring ways to improve their efficiency and scalability even further.
Transformers have revolutionized the field of natural language processing. Their self-attention mechanism allows them to understand context better than previous models.
They are efficient, scalable, and have achieved state-of-the-art results in many NLP tasks. They are also finding applications in other domains, such as computer vision and healthcare.
The future of transformers looks very bright. Researchers are constantly developing new and improved transformer architectures.
They are also exploring new applications for these powerful models. We can expect to see even more impressive results from transformers in the years to come.
Key Takeaways:
Transformers use self-attention to understand context by weighing the importance of each word in relation to others.
Positional encoding helps transformers understand word order, crucial for distinguishing meaning in different sentence structures.
Multi-head attention allows transformers to focus on different aspects of the input simultaneously, enhancing their understanding.
Transformers are highly efficient and scalable due to their ability to process input tokens in parallel.
They have revolutionized NLP tasks like machine translation, sentiment analysis, and text summarization, and are expanding into other areas like computer vision and healthcare.