GPT-2 is a large language model developed by OpenAI. It is the second iteration in the series of Generative Pre-trained Transformer models.
GPT-2 is designed to predict the next word in a sequence. It can generate remarkably coherent and contextually relevant text.
GPT-2 boasts several key features. It has a large number of parameters, up to 1.5 billion in its largest variant.
This model uses a transformer-based architecture. It was trained on a massive dataset of 8 million web pages called WebText.
It employs masked self-attention. This allows it to focus on relevant parts of the input sequence when generating text.
GPT-2 differs significantly from its predecessor, GPT-1. It has ten times more parameters and a much larger training dataset.
Unlike BERT, which uses bidirectional context, GPT-2 uses unidirectional, or left-to-right. This design choice makes it particularly effective for text generation tasks.
GPT-2 is also different from models like XLNet. It strictly adheres to an auto-regressive approach, generating one token at a time.
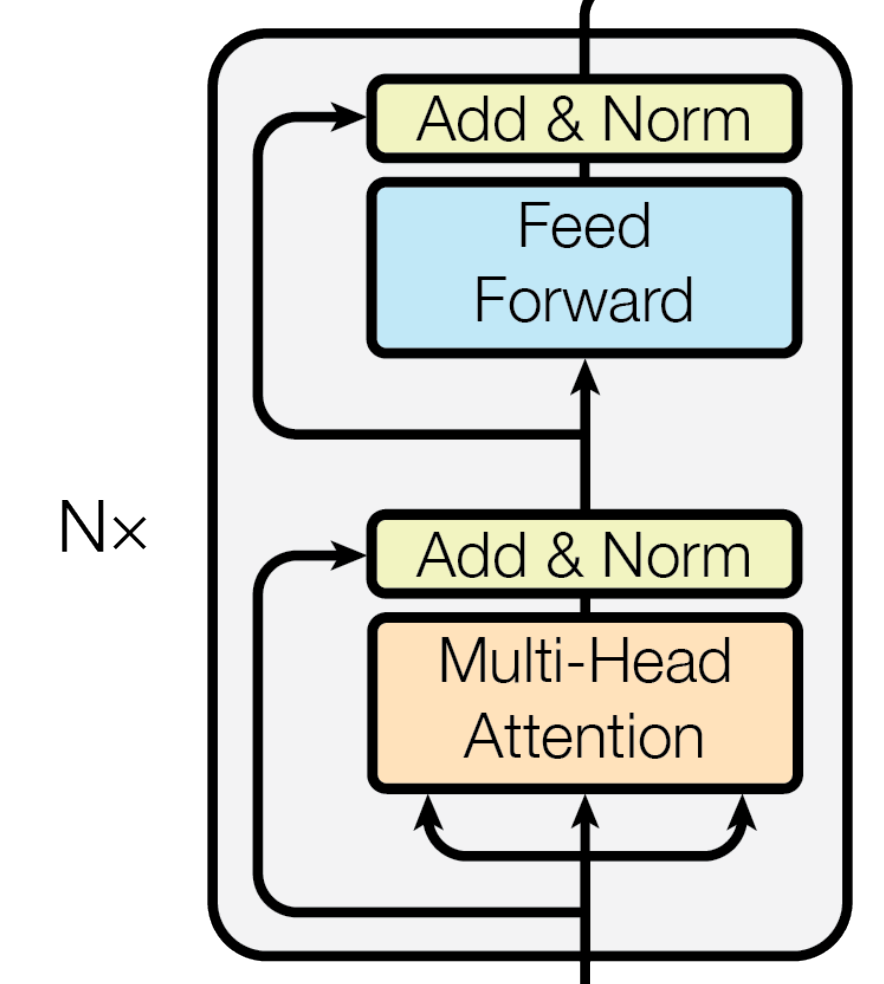
The transformer architecture, introduced in the paper "Attention is all You Need", is fundamental to GPT-2. It relies on self-attention mechanisms to weigh the importance of different words in the input sequence.
This architecture consists of an encoder and a decoder. However, GPT-2 only utilizes the decoder part.
In the original transformer, the encoder processes the input sequence. The decoder generates the output sequence.
GPT-2, being a decoder-only model, uses the decoder to both process the input and generate output. The encoder is used for tasks like language translation, while the decoder is more suited for text generation.
Self-attention allows the model to consider the entire input sequence at once. It determines the relevance of each word to every other word.
This mechanism helps GPT-2 understand context. It captures long-range dependencies within the text.
GPT-2 uses masked self-attention. This means that when predicting a word, the model only considers the words that come before it.
This is crucial for auto-regressive text generation. It ensures that the model does not "cheat" by looking at future tokens.
Masking is achieved by setting the attention weights for future tokens to negative infinity. This prevents them from influencing the prediction.
Before text is fed into GPT-2, it undergoes tokenization. This process converts raw text into a sequence of tokens.
GPT-2 uses Byte-Pair Encoding (BPE) for tokenization. BPE merges the most frequent pairs of bytes into a single token, allowing for efficient handling of large vocabularies.
GPT-2 generates text in an auto-regressive manner. It predicts one token at a time, using previously generated tokens as context.
This process continues until a stop condition is met. For example, reaching a maximum length or generating an end-of-sequence token.
The model takes a sequence of input tokens. It processes them through its layers to generate a probability distribution over the vocabulary for the next token.
The output token is selected based on this distribution. It is then added to the input sequence, and the process repeats.
GPT-2 was pre-trained on the vast WebText dataset. It contains millions of web pages.
The model can be fine-tuned for specific tasks. Fine-tuning involves training the pre-trained model on a smaller, task-specific dataset.
For stylistic continuation of input text, 5000 human comparisons result in the fine-tuned model being preferred by humans 86% of the time. Fine-tuning adjusts the model's weights to improve performance on the target task.
GPT-2 excels at generating coherent and contextually relevant text. It can be used for creative writing, content creation, and even drafting emails.
According to OpenAI's blog, the model adapts to the style and content of the conditioning text.
Researchers such as Gwern Branwen made GPT-2 Poetry. Janelle Shane made GPT-2 Dungeons and Dragons character bios.
GPT-2 can power chatbots capable of engaging in natural-sounding conversations. It can generate responses that are relevant to the ongoing dialogue.
The Hugging Face team fine-tuned GPT-2 to build a state-of-the-art dialog agent. They used the PERSONA-CHAT dataset.
Although not its primary focus, GPT-2 can perform machine translation. It can also summarize long texts into shorter, coherent summaries.
GPT-2 achieved 5 BLEU on the WMT-14 English-to-French test set. It outperformed several contemporary (2017) unsupervised machine translation baselines on the French-to-English test set, where GPT-2 achieved 11.5 BLEU.
To induce summarization behavior, the text "TL;DR:" was added at the end of the input texts. The model was configured to generate 100 tokens with top-k random sampling with k=2.
Understanding GPT-2 provides insights into the capabilities of modern language models. It helps beginners grasp the concepts behind transformer architectures and self-attention mechanisms.
This knowledge is valuable for anyone interested in natural language processing. It also has applications in artificial intelligence. You can learn more about the GPT-2 architecture for beginners.
GPT-2 represents a significant step forward in AI language models. It has paved the way for even more advanced models like GPT-3 and GPT-4.
Future models are likely to have even more parameters. They will be trained on larger datasets, and exhibit improved performance across a wider range of tasks.
These developments will further blur the lines between human and machine-generated text. They will open up new possibilities in various fields.
Key Takeaways:
- GPT-2 is a large language model developed by OpenAI, utilizing a transformer-based architecture with up to 1.5 billion parameters.
- It employs masked self-attention to generate text auto-regressively, predicting one token at a time based on previous tokens.
- GPT-2 was trained on a massive dataset of 8 million web pages, enabling it to produce high-quality, contextually relevant text.
- The model has diverse applications, including text generation, chatbots, machine translation, and summarization.
- Understanding GPT-2 provides valuable insights into modern language models and their potential, paving the way for future advancements in AI.