
Understanding Large Language Models (LLMs): An Overview
What Are Large Language Models?
Large Language Models (LLMs) are advanced AI systems. They are designed to understand, process, and generate human-like text.
Definition and Characteristics
LLMs are built on deep learning architectures, specifically transformer models. They are trained on vast amounts of text data from diverse sources like books, articles, and websites.
This extensive training enables them to learn intricate patterns and relationships within language. LLMs can perform tasks such as text generation, translation, summarization, and question-answering.
The Role of Neural Networks
Neural networks are fundamental to LLMs. Inspired by the human brain, these networks consist of interconnected nodes organized in layers.

They process input data through these layers. Each layer transforms the data, allowing the model to learn complex representations of language. You can learn more about them in this detailed explanation of how neural networks work.
How LLMs Function in Natural Language Processing
LLMs are integral to Natural Language Processing (NLP). They bridge the gap between human language and machine understanding.
Pre-Training and Fine-Tuning
The journey of an LLM begins with pre-training. It involves training the model on a massive dataset to predict the next word in a sequence.
After pre-training, LLMs are fine-tuned on specific tasks. This process tailors the model's capabilities to particular applications, such as sentiment analysis or chatbot interactions.
The Transformer Architecture
Introduced in 2017, the transformer architecture revolutionized NLP. It replaced recurrent networks with a self-attention mechanism.
This allows the model to weigh the importance of different words in a sequence. Thus, it captures long-range dependencies more effectively.
How LLMs Generate Text
The ability of LLMs to generate coherent and contextually relevant text is a marvel of modern AI. This is achieved through a sophisticated process involving tokenization, encoding, and decoding.
The Process of Text Generation
Text generation starts with an input prompt. The LLM processes this prompt and predicts the next word based on its training.
This process continues iteratively. Each new word becomes part of the input for the next prediction, enabling the creation of complete sentences and paragraphs.
Input Tokenization and Encoding
Before an LLM can process text, the input must be converted into a numerical format. Tokenization breaks down the text into individual words or subwords, called tokens.
Each token is then assigned a unique ID. Encoding maps these IDs to numerical vectors that the model can understand.
Decoding Strategies
Decoding is the process of selecting the next word in the sequence. LLMs use various strategies to balance creativity and coherence in the generated text.
Different Approaches to Decoding
There are several methods for decoding. Each has its own strengths and weaknesses.
Greedy Search vs. Beam Search
Greedy search is the simplest approach. It selects the most probable next word at each step.
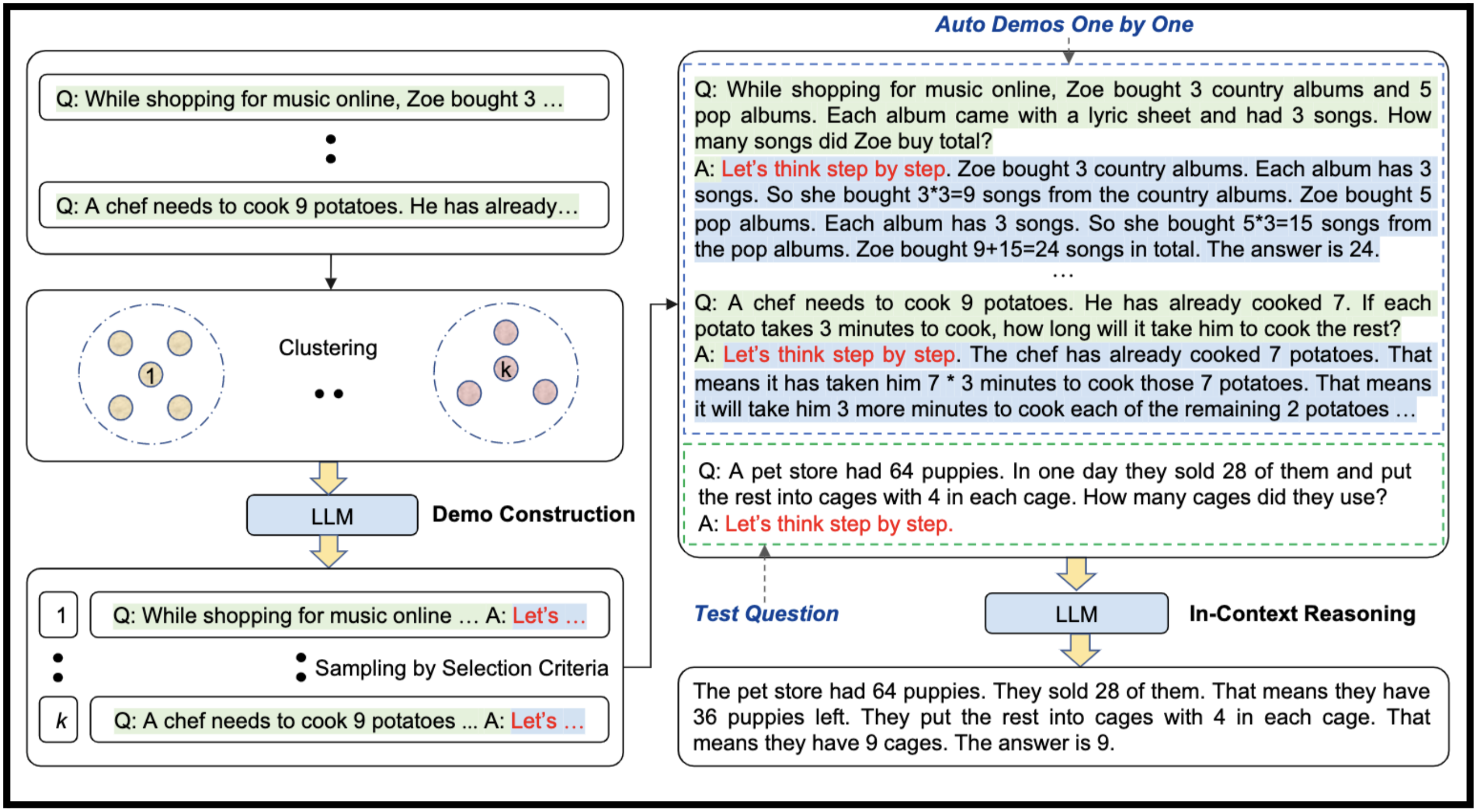
Beam search, on the other hand, considers multiple possible sequences. It keeps track of the top 'k' sequences, where 'k' is the beam width, as noted in this Huggingface guide. This often results in higher quality text but is computationally more expensive.
Stochastic Methods: Top-k and Top-p Sampling
Stochastic methods introduce randomness into the selection process. Top-k sampling limits the choice to the 'k' most likely words.
Top-p sampling, also known as nucleus sampling, considers the smallest set of words whose cumulative probability exceeds a threshold 'p'. These methods generate more diverse and creative text.
Temperature Control in Text Generation
Temperature is a hyperparameter that controls the randomness of the output. A higher temperature makes the output more random.
A lower temperature makes it more deterministic. This is well explained in the paper titled "A Thorough Examination of Decoding Methods in the Era of LLMs".
Applications of LLMs in Content Creation
LLMs are transforming the landscape of content creation. They offer innovative solutions across various industries.
Use Cases in Various Industries
The versatility of LLMs makes them valuable in numerous sectors. They are used to automate and enhance content-related tasks.
Content Generation for Marketing
LLMs can generate engaging marketing copy, social media posts, and product descriptions. They help create personalized content at scale, as highlighted in this Medium article.
Automated Customer Support and Chatbots
LLMs power chatbots that provide instant customer support. They can understand and respond to customer queries 24/7.
They offer a seamless and efficient customer service experience.
Creative Writing and Script Development
LLMs assist in creative writing tasks. They can generate story ideas, write scripts, and even compose poems.
They serve as a valuable tool for writers and artists.
Advantages of Utilizing LLMs for Content Creation
The adoption of LLMs in content creation brings numerous benefits. It streamlines processes and enhances creativity.
Speed and Efficiency
LLMs can generate content much faster than humans. They automate repetitive tasks and increase productivity.
Enhanced Personalization and Engagement
LLMs can tailor content to individual preferences. They analyze user data and create personalized experiences.
This leads to higher engagement and customer satisfaction.
Scalability and Cost-Effectiveness
LLMs enable businesses to scale their content creation efforts. They reduce the need for large teams of writers.
They offer a cost-effective solution for content production.
Challenges and Limitations of LLMs
Despite their impressive capabilities, LLMs are not without challenges. It is crucial to understand these limitations.
Technical Barriers to Development
Developing and deploying LLMs requires significant resources. There are technical hurdles to overcome.
Computational Requirements and Resource Needs
Training LLMs demands substantial computational power. It often requires specialized hardware like GPUs or TPUs.
The energy consumption of training large models is also a concern, as detailed in this article.
Data Privacy and Security Concerns
LLMs are trained on vast amounts of data. This raises concerns about data privacy and security.
Sensitive information in the training data can potentially be exposed.
Ethical Considerations
The use of LLMs brings ethical dilemmas to the forefront. It is essential to address these issues responsibly.
Hallucinations and Misinformation
LLMs can sometimes generate false or misleading information, known as hallucinations. This can have serious consequences.
It is crucial to verify the accuracy of LLM-generated content.
Bias and Fairness in Outputs
LLMs can inherit biases present in their training data. This can lead to unfair or discriminatory outputs.
Efforts are being made to mitigate bias and promote fairness in LLMs.
Future Directions and Innovations
The field of LLMs is rapidly evolving. Researchers are constantly exploring new ways to improve these models.
Emerging Trends in LLM Technology
There are several exciting developments on the horizon. They promise to enhance the capabilities of LLMs.
Improved Training Techniques and Algorithms
Researchers are developing more efficient training methods. They aim to reduce computational costs and improve performance.
New algorithms are being explored to enhance the reasoning abilities of LLMs, as discussed in this article.
Integration with Other AI Technologies
LLMs are being combined with other AI technologies. This includes computer vision and reinforcement learning.
These integrations create more powerful and versatile AI systems.
The Impact of LLMs on the Job Market and Society
The widespread adoption of LLMs will have profound implications. It is crucial to consider both the opportunities and challenges.
Opportunities for Businesses and Creators
LLMs offer new possibilities for businesses to innovate and streamline operations. They empower creators with tools to enhance their productivity and creativity.
Navigating Challenges and Ethical Implications
Society must address the ethical implications of LLMs. This includes job displacement and the spread of misinformation.
Promoting responsible use and development is essential.
Conclusion
LLMs represent a significant advancement in AI. They have the potential to revolutionize various aspects of our lives.
Summary of Key Insights
We have explored the definition, functionality, and applications of LLMs. We have also discussed the challenges and future directions in this field.
The Importance of Understanding LLMs
It is crucial for everyone to have a basic understanding of LLMs. They are becoming increasingly integrated into our daily lives.
Being informed allows us to harness their potential while mitigating risks.
Encouragement for Responsible Usage and Development
As we move forward, it is essential to prioritize ethical considerations. We should strive for transparency, fairness, and accountability in the development and deployment of LLMs.
Key Takeaways:
- LLMs are powerful AI models capable of understanding and generating human-like text.
- Text generation involves tokenization, encoding, and various decoding strategies.
- LLMs offer significant benefits in content creation, including speed, personalization, and scalability.
- Challenges include computational demands, data privacy, hallucinations, and bias.
- Responsible development and usage are crucial to harness the potential of LLMs while mitigating risks.